OLTP and OLAP Traversals
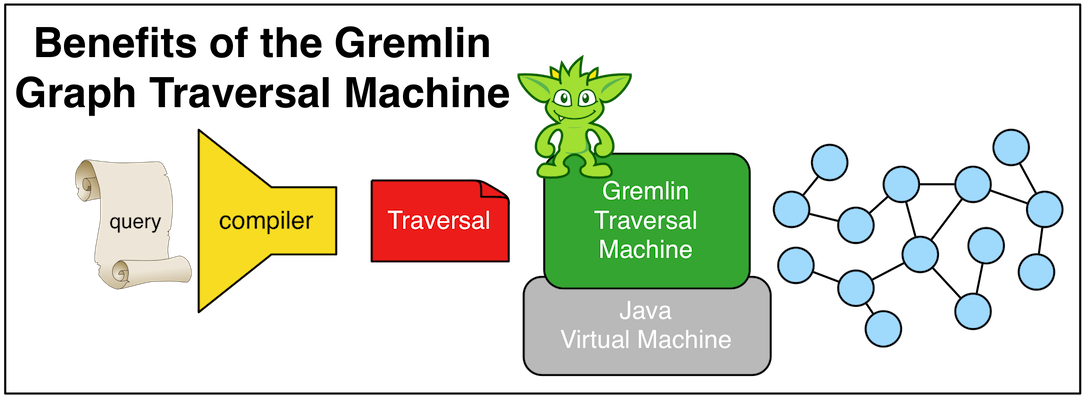
Gremlin was designed according to the "write once, run anywhere"-philosophy. This means that not only can all TinkerPop-enabled graph systems execute Gremlin traversals, but also, every Gremlin traversal can be evaluated as either a real-time database query or as a batch analytics query. The former is known as an online transactional process (OLTP) and the latter as an online analytics process (OLAP). This universality is made possible by the Gremlin traversal machine. This distributed, graph-based virtual machine understands how to coordinate the execution of a multi-machine graph traversal. Moreover, not only can the execution either be OLTP or OLAP, it is also possible for certain subsets of a traversal to execute OLTP while others via OLAP. The benefit is that the user does not need to learn both a database query language and a domain-specific BigData analytics language (e.g. Spark DSL, MapReduce, etc.). Gremlin is all that is required to build a graph-based application because the Gremlin traversal machine will handle the rest.

Imperative and Declarative Traversals
g.V().has("name","gremlin").as("a").
out("created").in("created").
where(neq("a")).
in("manages").
groupCount().by("name")
g.V().match(
as("a").has("name","gremlin"),
as("a").out("created").as("b"),
as("b").in("created").as("c"),
as("c").in("manages").as("d"),
where("a",neq("c"))).
select("d").
groupCount().by("name")
The user can write their traversals in any way they choose. However, ultimately when their traversal is compiled, and depending on the underlying execution engine (i.e. an OLTP graph database or an OLAP graph processor), the user's traversal is rewritten by a set of traversal strategies which do their best to determine the most optimal execution plan based on an understanding of graph data access costs as well as the underlying data systems's unique capabilities (e.g. fetch the Gremlin vertex from the graph database's "name"-index). Gremlin has been designed to give users flexibility in how they express their queries and graph system providers flexibility in how to efficiently evaluate traversals against their TinkerPop-enabled data system.
Host Language Embedding

The first example below shows a simple Java class. Note that the Gremlin traversal is expressed in Gremlin-Java and thus, is part of the user's application code. There is no need for the
developer to create a String representation of their query in (yet) another language to ultimately pass that String to the graph computing system and be returned a result set. Instead,
traversals are embedded in the user's host programming language and are on equal footing with all other application code. With Gremlin, users do not have to deal with the awkwardness exemplified
in the second example below which is a common anti-pattern found throughout the industry.
public class GremlinTinkerPopExample {
public void run(String name, String property) {
Graph graph = GraphFactory.open(...);
GraphTraversalSource g = traversal().withEmbedded(graph);
double avg = g.V().has("name",name).
out("knows").out("created").
values(property).mean().next();
System.out.println("Average rating: " + avg);
}
}
public class SqlJdbcExample {
public void run(String name, String property) {
Connection connection = DriverManager.getConnection(...)
Statement statement = connection.createStatement();
ResultSet result = statement.executeQuery(
"SELECT AVG(pr." + property + ") as AVERAGE FROM PERSONS p1" +
"INNER JOIN KNOWS k ON k.person1 = p1.id " +
"INNER JOIN PERSONS p2 ON p2.id = k.person2 " +
"INNER JOIN CREATED c ON c.person = p2.id " +
"INNER JOIN PROJECTS pr ON pr.id = c.project " +
"WHERE p.name = '" + name + "');
System.out.println("Average rating: " + result.next().getDouble("AVERAGE")
}
}
Behind the scenes, a Gremlin traversal will evaluate locally against an embedded graph database, serialize itself across the network to a remote
graph database, or send itself to an OLAP processor for cluster-wide distributed execution. The traversal source definition determines where the traversal executes. Once a traversal source is
defined it can be used over and over again in a manner analogous to a database connection. The ultimate effect is that the user "feels" that their data and their traversals are all
co-located in their application and accessible via their application's native programming language. The "query language/programming language"-divide is bridged by Gremlin.
Graph graph = GraphFactory.open(...);
GraphTraversalSource g;
g = traversal().withEmbedded(graph); // local OLTP
g = traversal().withRemote(DriverRemoteConnection.using("localhost", 8182)) // remote
g = traversal().withEmbedded(graph).withComputer(SparkGraphComputer.class); // distributed OLAP